PromptShield
A free, open-source proxy for every LLM call. Rate limiting, audit logging, provider routing, and Prometheus metrics out of the box. PII scanning and injection blocking coming soon.
Most teams wire their app directly to an LLM API and figure out observability, rate limits, and safety later. PromptShield flips that.
It sits between your app and any LLM, giving you rate limiting, structured audit logs, token tracking, and full Prometheus metrics from day one. No application code changes. Free and open source.
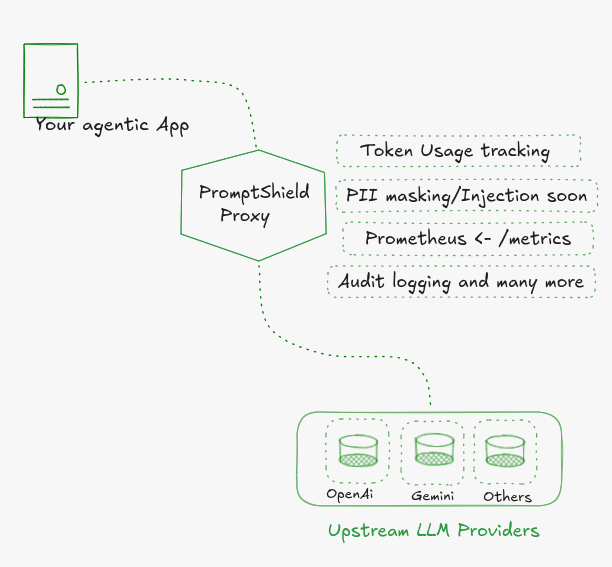
Drop it in front of Gemini, OpenAI, Ollama, or anything OpenAI-compatible. Change base_url in your SDK. Done.
What you get today
Rate limiting: Token bucket per IP or per API key. Configurable requests/min and burst. Returns HTTP 429 before your LLM is ever called. Zero tokens consumed.
Audit logging: Every request writes one NDJSON line to stdout: request ID, provider, model, action, token counts, latency. No config. Always on. Pipe it to Loki, CloudWatch, or a local file.
Prometheus metrics + Grafana dashboard: Built-in /metrics endpoint. A pre-built Grafana dashboard ships in infra/observability/ covering request rate, p50/p95/p99 latency, token burn by model, block rate, and error rate. One docker compose up and it's live.
Multi-provider routing: Gemini, OpenAI, Ollama, and any OpenAI-compatible endpoint (Groq, Together, Fireworks, Anyscale). Switch providers with one env var.
OpenAI-compatible endpoint: Your SDK doesn't know it's talking to a proxy. Point base_url at PromptShield and nothing else in your app changes.
Coming soon: detection engine (optional)
The detection engine is a separate service that adds a security layer on top of the proxy. When it is running, every prompt passes through it before the model ever sees it.
PII detection: Finds emails, phone numbers, credit cards, SSNs, IBANs, and 15+ other entity types. Your policy.yaml decides whether each type gets blocked, masked, or allowed.
Injection detection: Catches patterns like "ignore previous instructions", "reveal your system prompt", and other jailbreak attempts.
Response scanning: Applies the same policy to LLM responses before they reach your app. Catches data the model might echo back or hallucinate.
Policy enforcement: One YAML file. Per entity type. Version-controlled alongside your code.
| Action | What happens |
|---|---|
block | HTTP 403 returned. LLM never called. Zero tokens consumed. |
mask | PII replaced with [ENTITY_TYPE]. Sanitized prompt forwarded. |
allow | Passes through unchanged. |
The proxy runs fully without it. You won't get PII scanning or injection blocking.
Two modes
Gateway mode: No detection engine. Rate limiting, token tracking, provider routing, audit logs, and Prometheus metrics. Start here. This is what the proxy does today.
Security mode (coming soon): Full PII + injection scanning on every request. Block or mask based on policy.yaml. Optional response scanning. Zero extra application code.